SQL Server 2014 Yenilikleri 4 - In-Memory DW - ColumnStore Index (26.10.2016)
Yeni nesil teknolojiler, yüksek bellek ve daha çok çekirdekli güçlü işlem yeteneğine sahip modern donanımlar sayesinde veri işleme süratini günden güne arttırmaktadır. Microsoft, SQL Server ürününü bu trend doğrultusunda geliştirmekte ve hem analitik işlemler için hem de çekirdek veri tabanı işlemleri için In-Memory teknolojilerini ön plana çıkarmaktadır.
PowerPivot ve Analysis Services gibi analitik hizmetlerde kullanılan In-Memory teknolojisi geliştirilerek In-Memory OLTP veIn-Memory DW(ColumnStore Indexes) başlıkları ile veri tabanı motorlarında(Database Engine) da kullanıma sunulmuştur.
Önceki yazımızda daha çok INSERT, UPDATE, DELETE performansını arttırmak amacıyla geliştirilen In-Memory OLTP motorunun çalışma esaslarına değinmiştik. Şimdi ise SELECT performansını 10 kat, bazı durumlarda 100 kat arttırabilen ve In-Memory DW başlığı altında yer alan ColumnStore konseptini inceleyeceğiz.
SQL Server önceki versiyonlarında verileri sadece Heap ve B-tree yapılarda yönetmekteydi. SQL Server 2012 ile birlikte In-Memory kapsamına giren yeni bir index türü daha duyuruldu. Böylece çekirdek veri tabanı işlemlerinde de In-Memory teknolojisi kullanılabilir hale geldi.
Non-Clustered ColumnStore Index adıyla duyurulan bu index, verileri Heap ve B-tree yapıdakinden farklı olarak satır odaklı değil, kolon odaklı tutmaktadır. Bu yeni yaklaşım, birkaç kolonun fakat birçok satırın çağrıldığı sorgu sonuçlarının etkileyici hızda elde edilmesini sağladı. Hatta satır sayısı belli bir sınırı aştıktan sonra performans artışı çok daha fazla olmaktadır.
Bank of Nagoya’dan direktör yardımcısı Atsuo Nakajima; SQL Server 2012 In-Memory ColumnStore’u kullanarak 100 milyonsatırı 30 dakika yerine artık 2 veya 3 saniyede elde edebildiklerini ifade etmiştir. Başka bir örnekte, star şemanın tercih edildiği bir veri ambarında, 2 milyar satır bulunun fact tablosu kullanılarak üretilen rapor önceden 18 saatte açılmaktayken, ColumnStore teknolojisi sayesinde aynı donanım üzerinde 5 dakikada açıldığı gözlemlenmiştir. Bir diğer örnekte ise; fact tablosunun tarandığı bir veri ambarından 17 dakikadan fazla sürede elde edilen sorgu sonucunun bu yeni index türü sayesinde 3 saniye civarında getirildiği tecrübe edilmiştir.
Sonuçlar oldukça etkileyici görünüyor. Fakat sayılar çok farklı olduğu için inandırıcı gelmemiş olabilir. Aldığımız sonuçlar özetle; işlemci çekirdek sayısına, memory büyüklüğüne, talep edilen satır sayısının belli bir sayıdan fazla olmasına ve sorguların veri ambarı benzeri(Star, SnowFlake şema dizaynlı) sistemlerde kullanılanlar gibi olmasına bağlıdır. Son kısma bir açıklık getirmek gerekirse; tüm tablonun çağrıldığı bir sorgu performansı sizi etkilemeyecektir. Ancak daha az kolonun ve daha fazla satırda daha karmaşık işlemlerin yapıldığı gruplama sorgularının performansını görmek hoşunuza gidecektir.
ColumnStore index nasıl bir şey?
Fiziksel olarak bağımsız işlem gören kolonlar halinde, mantıksal olarak satır ve sütunlarla tablo şeklinde organize edilen veriye columnstore denir. Verileri bu formatta depolayan ve yöneten yeni index türüne ise ColumnStore index adı verilmektedir.
ColumnStore index verileri, sıkıştırır ve segment adı verilen kolon odaklı parçalar halinde depolayıp yönetir. Sorgulama sırasında Query Optimizer columnstore indexleri mi yoksa diğer indexleri mi kullanacağına kendisi karar verir. Elbette çeşitli sorgu hintleri kullanarak index kararlarına müdahil olmak mümkündür.
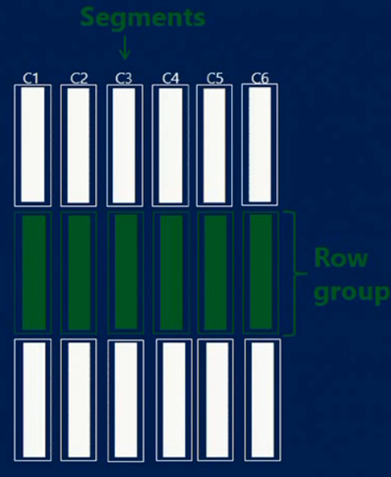
ColumnStore indexin temel yapısı şu şekildedir:
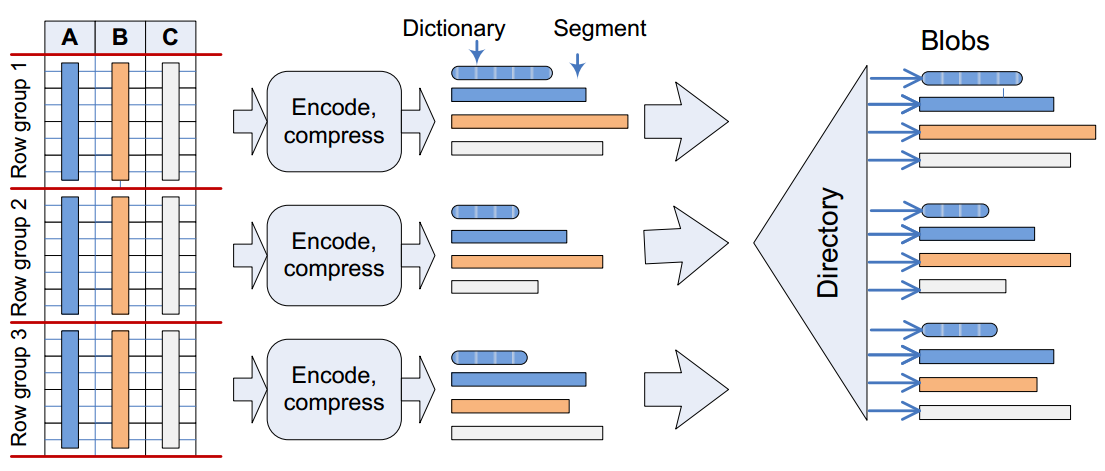
Bu yapıda yaklaşık her 1 milyon satır “row grup”lara bölünür. Row gruplar içerisinde ayrı ayrı sıkıştırılan ve kodlanan paralel kolonlar “segment”leri oluşturur. Segmenler disk ile memory arasında transfer olan birimlerdir. Bu resimde A,B,C kolonlarından oluşan satırlar 3 “row group”a ve toplamda 9 “segment”e bölünmüştür. Bu “segment”ler hakkında satır sayısı, büyüklük ve maksimum, minimum değerler için metadata bilgisi directoryde tutulmaktadır. Segmentler ve encoding bilgisinin tutulduğu “dictionary” disk pagelerine blob(LOB) nesneleri olarak kaydedilir.
Veriler talep edildiğinde “segment” ve “dictionary”ler memoryden gelir. Ancak bunun için buffer cache değil direkadjacent(bitişik) memory pageler kullanılır. Dolayısıyla page split derdi olmamaktadır.
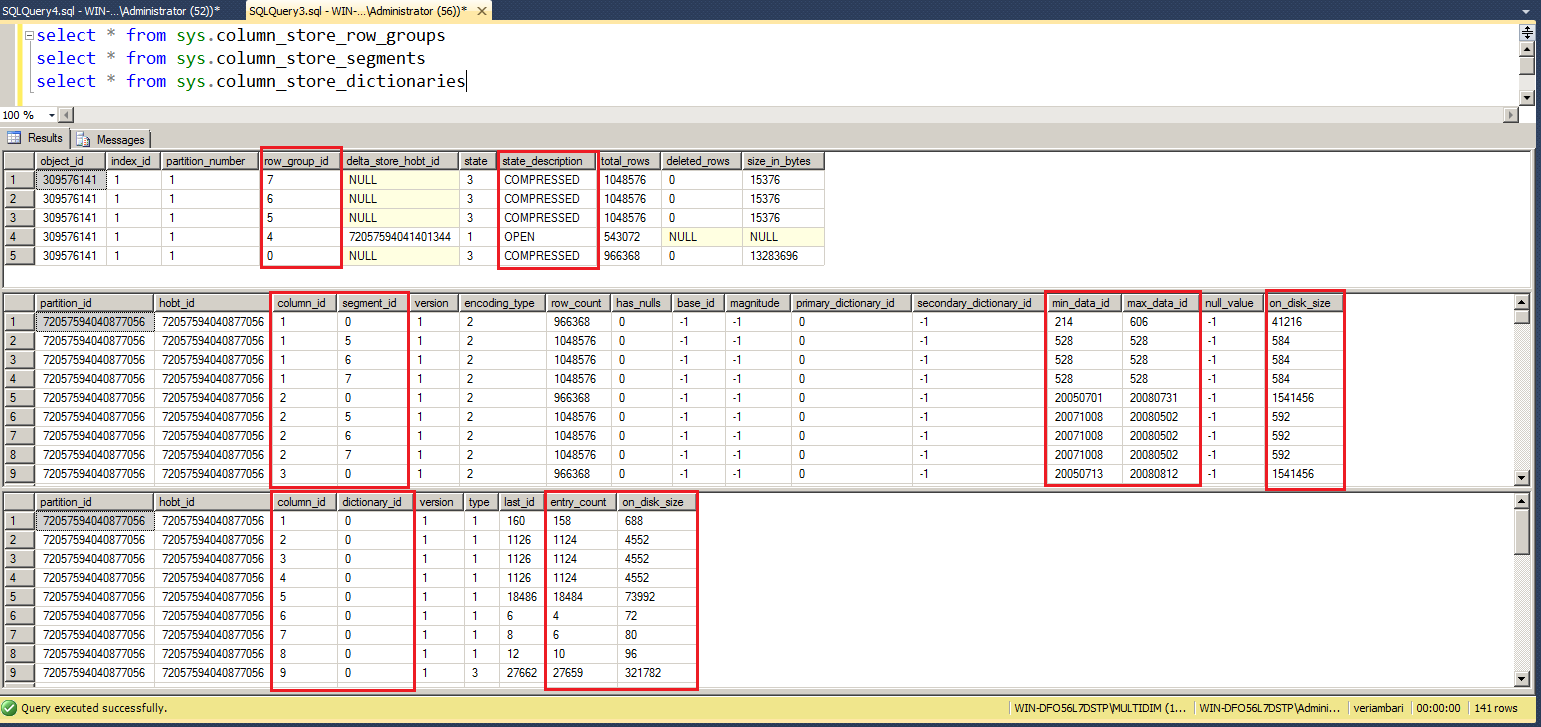
Row group, segment ve dictionary hakkındaki bilgileri şu sorgularla inceleyebilirsiniz:
Performansı bu kadar arttıran şey nedir?
Bunu genel olarak şu 3 başlık altında inceleyebiliriz:
1- Fiziksel yapı
Heap ve B-tree yapıda veriler sıkıştırılmadan pagelerde satır odaklı tutulmaktadır. Yani indexlenen her kolon sorguda istenmese de getirilen pagelerde yer alır. Columnstore yapıda ise veriler sıkıştırılarak segmentlerde kolon odaklı tutulur. Yani istediğiniz kolonlar için sadece o kolonun bilgisinin bulunduğu segmentler çağrılır. Bazı segmentler diğerlerinden fazla sıkıştırılabilmektedir.
Çoğu zaman sorgularımızda kullandığımız kolonlar indexlediğimiz kolonlardan daha az sayıda olmaktadır. Özetle B-tree yapıda istediğimiz kadar veriyi elde etmek için daha fazla page okumamız gerekirken columnstore yapıda çok daha az segment okuması yaparak aynı sonuca ulaşabilmekteyiz.
2- Batch Mode işleme
SQL Server sorgu operatörleri geleneksel olarak tek seferde bir satır işlemektedir. Yani sürekli “row mode”da çalışmaktadır. Columnstore ile birlikte tek seferde bir grup(batch) satır işleyen yeni operatörler getirildi. Bu özellik yoğun hesap gerektiren işlemden geçecek binlerce satırın daha yüksek hızda elde edilmesini sağlamaktadır. Scan, filter, Project, hash(inner) join ve (local)hash aggregation SQL Server 2012’de “batch mode”u destekleyen sorgu operatörleridir.
Query Optimizer row mode veya batch mode tercihini şu şekilde yapar; binlerce satır filtreleme, birleştirme, gruplama ve yoğun hesapların olduğu işlemlerden geçmesi gerektiğinde batch modeu tercih eder, daha az veride ve batch modu desteklemeyen sorgu operatörleri kullanıldığında row modeu tercih eder.
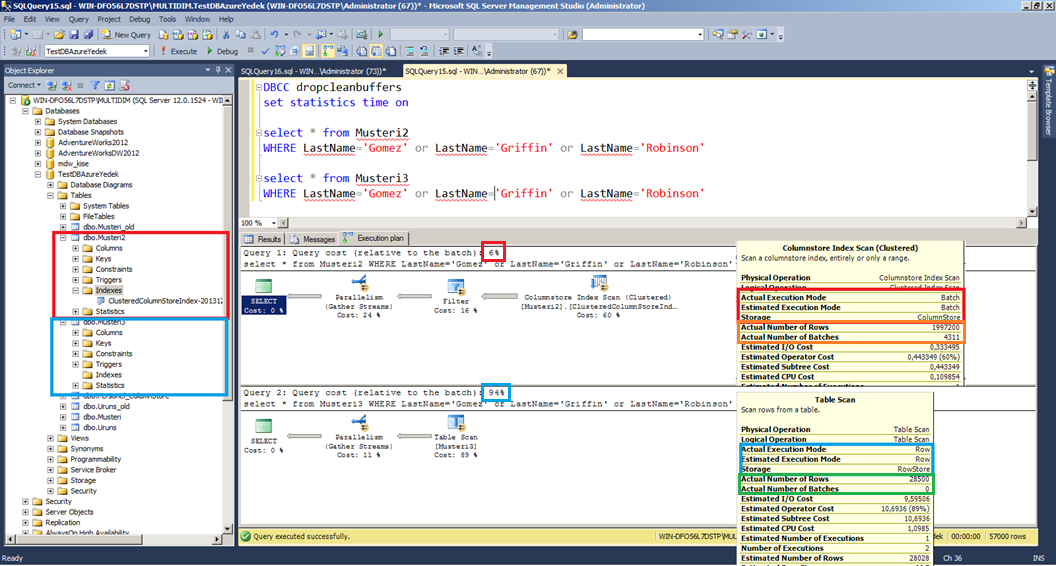
Aşağıdaki örnekte Musteri2 tablosunda ColumnStore index kullanıldı fakat Musteri3 tablosunda herhangi bir index kullanılmadı. Musteri 3 tablosunda aynı filtre için çok daha az sonuç getirecek kadar veri olmasına rağmen(2 milyona 30 bin) çalışma modundan(row-batch) dolayı ColumnStore indexli tabloya yapılan sorgunun diğer sorgu karşında sisteme olan maliyeti %6 da kalmış durumda.
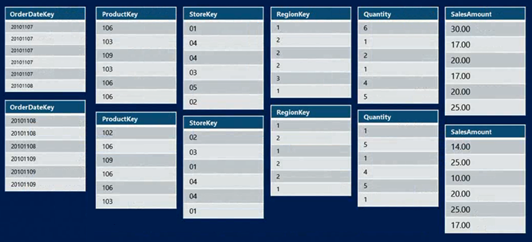
3- Segment eleme
Bu özellik sayısal ve tarihsel alanlarda işe yaramaktadır. Filtre ve join gibi işlemlerde devreye giren bu özellik sayesinde storage engine sadece gerekli segmentleri diskten okur. Diğer segmentleri atlar.
Aşağıdaki örnekte 20080631 değerinden büyük olan OrderDateKey’ler sadece 0 segmentinde bulunmaktadır. Bu sebeple diğer segmentler elimine edilerek sadece 0 segmenti diskten okunacaktır.
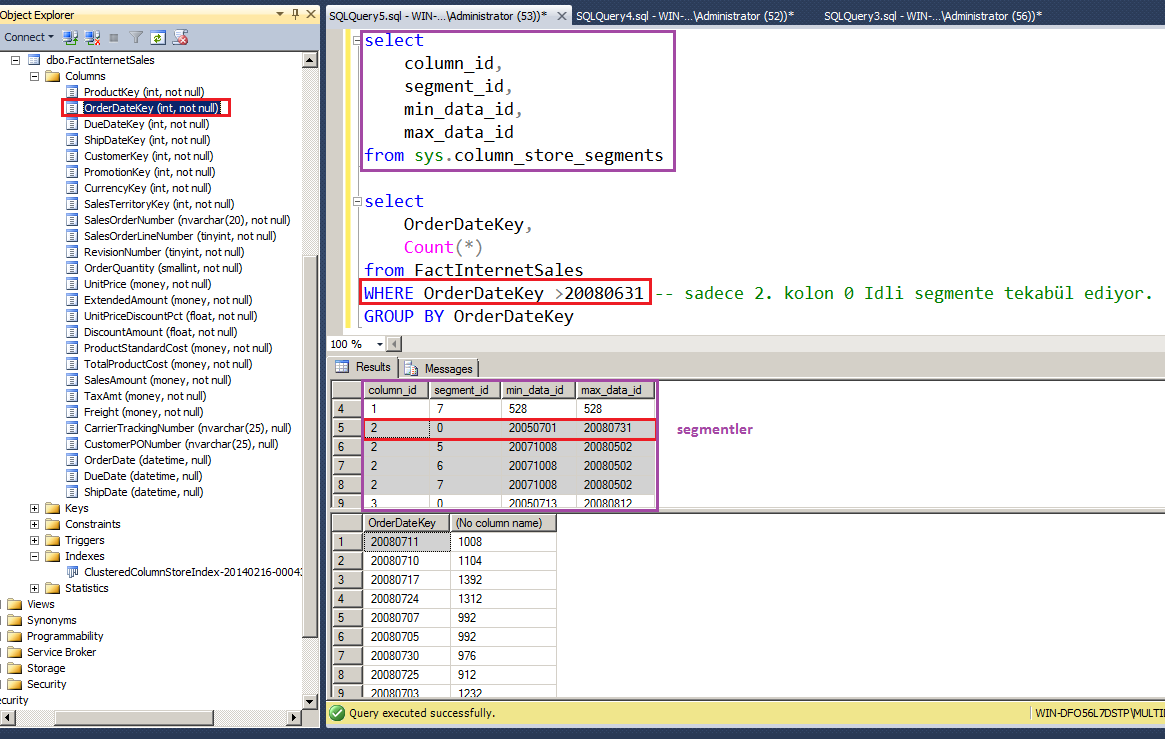
Kaç çeşit ColumnStore index vardır?
İki çeşit ColumnStore Index bulunmaktadır. İkisini de ara yüz yardımıyla oluşturmak mümkündür. Ancak uzun sürebilecek indexleme işlemleri için kodlarla çalışmayı tavsiye ederim.
Bu indexler neler bir göz atalım:
1- Non-Clustered ColumnStore index
 Bu index türü SQL Server 2012 ile birlikte duyuruldu.
Bu index türü SQL Server 2012 ile birlikte duyuruldu.
Bir tabloda tek bir non-clustered columnstore index olabilir. Fakat diğer B-Tree indexler tablo üzerinde yer alabilir. Tabloda constraintler tanımlanabilir. Primary ve Foreign Keyler kullanılabilir.
Ancak non-Clustered Columnstore indexin tanımlığı olduğu tablolarda yalnızca okuma işlemiyapılabilmektedir. Insert, Update, Delete işlemi yapabilmek için öncelikle bu indexin kaldırılması veya disable edilmesi gerekir. Sonra rebuild edilebilir.
Şu şekilde oluşturabiliriz:
CREATE NONCLUSTERED COLUMNSTORE INDEX IndexAdi ONTabloAdi
(
Col1,
Col2
)
Okuma performansını etkileyici bir biçimde arttıran bu indexten dolayı tablonun güncellenememesi maalesef ciddi bir problem olabilmektedir. Sırf bu sebeple kısa aralıklarla güncellenen sistemlerde bu index türü tercih edilmemektedir.
Nihayet yapı biraz daha geliştirildi ve yeni versiyonla birlikte Clustered ColumnStore adında update edilebilir bir columnstore index türü daha duyuruldu.
Şimdi asıl konumuz olan bu Clustered ColumnStore indexe odaklanalım.
2- Clustered ColumnStore index
 SQL Server 2014 ile birlikte gelecek olan bu index tüm tabloyu depolar ve bir tabloda hem tek bir clustered index tanımlanabilir hem de sonrasında başka hiçbir index tanımlanmasına izin verilmez. Açıkçası başka bir indexe artık ihtiyaç kalmayacaktır.
SQL Server 2014 ile birlikte gelecek olan bu index tüm tabloyu depolar ve bir tabloda hem tek bir clustered index tanımlanabilir hem de sonrasında başka hiçbir index tanımlanmasına izin verilmez. Açıkçası başka bir indexe artık ihtiyaç kalmayacaktır.
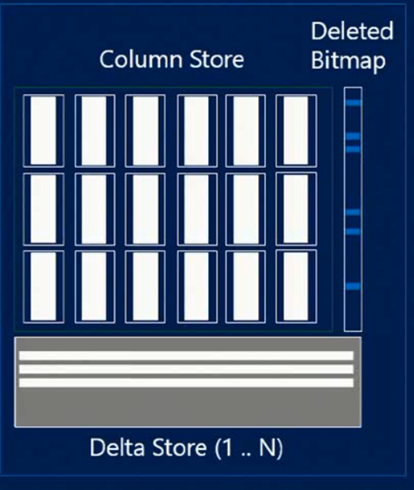
Clustered ColumnStore indexin en büyük getirilerinden birisi; tanımlandığı tablo üzerindeinsert, update, delete işlemlerinin yapılabiliyor olmasıdır.
Bu işlemlerin yapılabilmesi için ek iki bileşene daha ihtiyaç duyulmuştur. Bunlar insert edilen kayıtların belli bir sayıya kadar tutulduğu Delta Store, diğeri ise silinen satırların silindi diye işaretlenebilmesi için row ID’lerinin tutulduğu Deleted Bitmap dir. Her ikisi de verileri B-Treeyapıda barındırır.
Updateable Clustered ColumnStore index nasıl çalışıyor?
Insert: öncelikle insert edilen satırlar row grupun alabileceği maksimum satır sayısına ulaşana kadar Delta Store da bekletilir. Maksimum satır sayısına ulaşan her grubun durumu CLOSED olarak işaretlenir. Tuple Mover adı verilen bir arka plan işlemi default olarak her 5 dakikada bir devreye girerek CLOSED durumundaki satır gruplarını segmentlere bölüp sıkıştırır ve columnstore yapıya ekler. Sonra row groupların durumu COMPRESSED olarak belirtilir.
Bulk Load: 100 bin satırdan daha az veriler Delta Store da tutulur. Daha fazlası 1milyon satırı bir arada tutan row grouplar halinde direk columnstore yapıya eklenir.
Delete: silinen satırların satır ID leri Deleted Bitmapde tutularak satırlar silindi diye işaretlenmiş olur.
Update: bu işlem insert ve delete işleminin birleşimidir.
Clustered Columnstore index şu kodlarla oluşturulabilmektedir:
CREATE CLUSTERED COLUMNSTORE INDEX IndexAdi ON tabloAdi
Okuma performansı ne durumda?
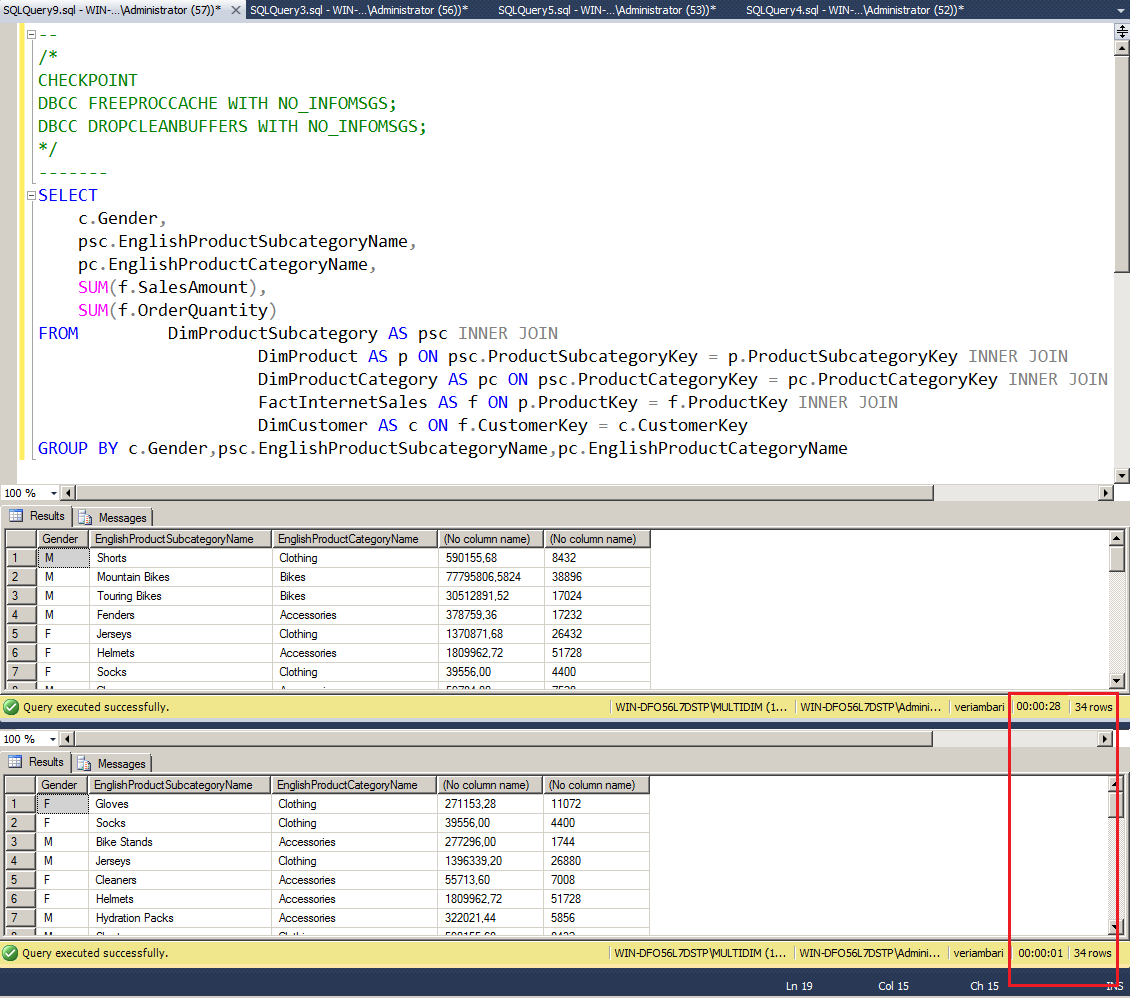
Yazımın başında bazı gerçek hayat örnekleri vermiştim. Bu sonuçlar oldukça etkileyiciydi. Şimdi ise ek olarak az önce kendi bilgisayarımda basitçe denediğim bir örneği sizlerle paylaşmak istiyorum.
Gelen satır sayısı çok az olmasına(34) yani row mode da çalışılmasına rağmen. 5 milyon satırlık fact tablosu üzerindeki toplama işlemi normalde 28 saniyede tamamlanırken Clustered ColumnStore index sayesinde 1 saniyede tamamlandı. Daha fazla satırda ve daha karmaşık işlemlerde aradaki fark iyice açılacaktır.
Ekleme ve Silme Performansları ne durumda?
Silme performansı B-tree yapıya göre daha yüksek. Çünkü B-tree yapıda veriler pagelerden gerçekten siliniyor(daha fazla storage işlemi) ve loga daha fazla kayıt giriliyor. columnstore yapıda ise sadece Deleted Bitmap de silindi diye işaretleniyor.
Kayıt girme esnasında ise veriler anında sorgulanabiliyor. Bunu sürekli kayıt giren bir sonsuz döngü açarak test edebilirsiniz. Bu esnada yeni kayıtları hızla elde edebildiğinizi göreceksiniz. Tabi ki daha sonra Tuple Moverın girilen verileri columnstore yapıya eklemek için arka planda çalışması gerekecektir.
Veri sıkıştırma(Compression) özelliği ne kadar etkili?
Normalde tablo veya partitionlarda page ve row sıkıştırma özelliği mevcuttur. Eğer bir tabloda Clustered ColumnStore index tanımlanırsa bu tablonun sıkıştırma tipi “Columnstore” olur.
Eğer daha yüksek sıkıştırmaya ihtiyacımız olursa Columnstore_Archive özelliğini kullanabiliriz. Bu sayade 15 kata varan sıkıştırma sonuçları elde edilebilir. Bu oran elbette veri tekrarına ve veri tiplerine bağlıdır. Ayrıca okuma ve yazma işlemleri sırasında CPU yükünün artacağı da göz önünde bulundurulmalıdır. Columnstore_Archive sıkıştırma tipi okuma işleminin nadir olduğu yazma işleminin de neredeyse hiç olmadığı arşiv verilerinden yer kazanmak için tercih edilmelidir.
Aşağıdaki grafikte 101 milyon satırlık bir tablo, index ve uygulanan sıkıştırma tipleri ile ilgili bazı sonuçlar yer almaktadır.
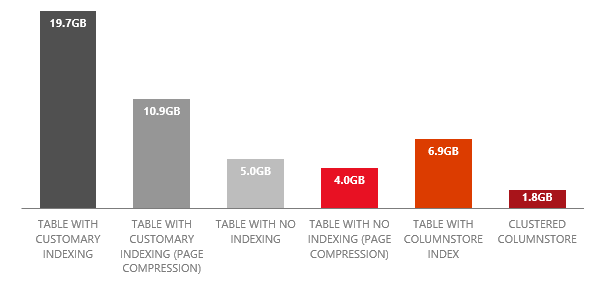
Bu sonuçlardan biraz bahsedelim...
5 GB lık tablo üzerinde index tanımladığımızda 19.7 GB alanı rezerve etmek zorunda kalabiliyoruz. Bu durumda Page compression uygulasak bile 10.9 GB’a düşülebiliyor.
Üzerinde index bulunmayan bu tabloyu page compression ile sıkıştırırsak 1GB yer kazanabiliyoruz ancak bu yaklaşım okuma performansımıza hiçbir katkı sağlamayacaktır.
Tablo üzerinde tanımladığımız Non-Clustered ColumnStore index bir miktar daha yer kaplayarak alan ihtiyacını 6.9GB’a çıkartmış durumda.
Aynı tablo üzerinde Clustered ColumnStore index tanımlarsak. Tüm veri 1.8 GB’a sıkıştırılabilir.
Biraz daha fazla alan kazanmak için ColumnStore_Archive tercih edilebilir. Bu işlemi bir tablo için şu kod yardımıyla yapabiliriz.
ALTER TABLE TabloAdi
REBUILD WITH (DATA_COMPRESSION=COLUMNSTORE_ARCHIVE)
Bir örnekte 2 milyon satırlık ve 105 MB’lık bir tablo ColumnStore sıkıştırma tipi ile 10 MB’a, ColumnStore Archive sıkıştırma tipi ile 4MB’a kadar indi. Örneğimizde 101MB’lık yer kazanmış olduk.
Bu sıkıştırma teknolojileri veri tabanı boyutunu %27’lere kadar düşürebilmektedir.
Artık diğer indexleri kullanmamıza gerek kalmadı diyebilir miyiz?
Tabi ki hayır, Clustered columnstore index tanımlanacak tablo üzerinde trigger tanımlanmamış olması gerekir. XML, varbinarygibi veri tiplerine destek verilmemektedir. Primary Key, Foreign Key ve başka indexlerle birlikte kullanılamamaktadır. Yani bu ve benzeri gereksinimler olduğu sürece hala diğer indexlere ihtiyacımız var demektir.
Ne tür sistemler için uygundur?
Verinin daha az yazılıp çok defa okunduğu sistemlerde, karmaşık filtreleme ve gruplama işlemlerinin yapıldığı büyük ölçekli verilerde, star ve snowflake şema dizaynı benimsenmiş fact ve dimension tablolarından oluşan veri ambarlarında kullanılması uygundur.
İncelediklerimizi bir özetlemek gerekirse;
SQL Server 2014 ile birlikte In-Memory DW olarak adlandırılan ColumnStore yapının temelleri PowerPivot ile analitik sistemlerde atılmıştı. Bu teknoloji SQL Server 2012 ile birlikte tabular ile yine analitik sistemde ve Non-Clustered ColumnStore index ile çekirdek veri tabanı sisteminde kendini gösterdi. Tanımlandığı tabloyu sadece read-only erişime açan non-clustered columnstore index güncelleme işlemlerinde ayak bağı olabilmekteydi. Biraz daha geliştirilen ColumnStore yapısı,SQL Server 2014‘te kullanıma sunulacak olan Clustered ColumnStore index ile birlikte güncelleme işlemlerinin yapılabilmesini mümkün hale getirdi. Bu sayede In-Memory daha geniş sistemlerde kullanılabilir hale geldi diyebiliriz.
In-Memory DW başlığı altında incelediğimiz bu yapı sayesinde 100 kata varan hız, 15 kata varan sıkıştırma elde edebiliyoruz. Kısıtları ile barışık bir sisteme uygulanırsa donanım değişikliğine gitmeye gerek kalmadan kısa sürede kullanıcılarının yüzünü güldüreceğe benziyor.
Abdullah KİSE
Veri Yönetimi ve İş Zekâsı Ekibi